Blazing Fast PSI from Improved OKVS and Subfield VOLE
来自改进的 OKVS 和 VOLE 子域的极速 PSI
我们提出了新的半诚实和恶意安全的 PSI 协议,这些协议在通信和运行时间上都比之前的所有作品要好几倍。例如,我们对
首先是对 Rindal 等人的协议进行了优化,利用子域向量不经意线性评估。这一优化使我们的结构首次实现了
我们的第二个改进是对 OKVS 数据结构的改进,我们的协议主要依赖于这个结构。特别是,与之前的工作相比,我们的结构提高了计算和通信效率(Garimella 等人,Crypto 2021)。这些改进源于对数据结构的算法改变,以及获得其失败概率的渐进和严格的具体界限的新技术。这反过来又允许高度优化的参数选择,从而提高性能。
1 介绍
隐私集合求交集:在这项工作中,我们提出了新的改进措施,以有效地执行隐私集合求交集(PSI)。在这里,两个相互不信任的各方,分别持有一组数值
PSI 可以追溯到 20 世纪 80 年代 [Mea86],最初是基于 OPRFs 和 Diffie-Hellman。事实上,几个现代协议 [CT10, IKN+20, BKM+20] 仍然是基于 [Mea86] 的协议。随着不经意传输扩展(OT extension)的发明 [IKNP03],Schneider 等人 [PSSZ15] 开始了对一个新协议系列的研究,同时还有许多衍生协议 [PSZ14, KKRT16, RR17, OOS17, PRTY19]。这些协议以增加通信量为代价提供了更好的效率。
然而,随着 [PTY20] 和 [RS21, GPR+21] 密切相关的协议的出现,情况已经开始改变。[PRTY20] 引入了一种叫做 OKVS 的新数据结构,它提供了一种非常方便的方式来表示集合
我们观察到,最近对 VOLE [CRR21] 和 OKVS [GPR+21] 的改进可以应用于 [RS21]。虽然这确实进一步降低了 [RS21] 的通信复杂性,但由于 [GPR+21] OKVS 数据结构的计算开销,该协议的运行时间仍然比 [KKRT16] 慢。我们将介绍对 [PRTY20, GPR+21] 的 OKVS 的重大改进,以及进一步减少 [RS21] 通信开销的新技术。
我们进一步注意到,我们的改进也转化为其他几个 PSI 相关的功能。其中最重要的一个是电路 PSI [HEK12, PRTY19, RS21]。该功能类似于普通的 PSI,除了输出是双方共享的秘密。当需要在揭示交集之前对其进行额外的加密计算时,这可能特别有用,例如,计算基数或相关值的总和 [IKN+20]。我们将我们的新技术应用于该协议,并观察到对于一百万的集合大小,运行时间和通信量分别减少 6.8 倍和 2.3 倍。
其他功能包括 [NTY21] 的多方 PSI 协议使用了 OKVS 和被称为 OPRF 或 OPPRF 的基元,可以利用我们的改进。我们把我们的工作应用于这个协议和其他许多协议作为未来的工作。
不经意键值存储 OKVS:前面提到的数据结构被称为不经意键值存储(Oblivious Key-Value Stores, OKVS),由算法
在 PaXoS [PTY20] 中,
然而,这个过程很可能无法对输入的一个小子集进行编码。众所周知,这个子集的大小最多为
[GPR+21] 提出对上述结构进行概括,使
关于 PSI 的更多相关工作,我们参考 [RS21],关于先前 OKVS 方案的更多细节,参考 [GPR+21]。
1.1 我们的贡献
在这项工作中,我们提出了一个改进的 OKVS 结构,并将其与 VOLE 子域一起作为一个构件,以获得迄今为止最快和最高效的 PSI 协议。
- 我们提出了一个框架,从理论上和具体上理解与基于布谷鸟散列的随机 OKVS 结构有关的失败概率。
- 在我们工作的参数和分布范围内,我们的 OKVS 编码器以压倒性的概率成为 "最优"。
- 有了上面的理解,我们推导出 OKVS 的构造,在紧凑性和运行时间方面大大超过了现有技术水平。
- 我们的 OKVS 包括对现有技术的一些优化,包括将总行权重减少 10 倍,
密集列,无递归结构,以及聚类。 - 通过采用我们改进的 OKVS 以及我们对 [RS21] 中提出的 OPRF 和 PSI 结构的新优化,我们获得了迄今为止最高效的 PSI 协议。这些改进使我们的结构能够在 0.37 秒和 0.16 秒内完成一个
项的 PSI,分别在单线程和多线程设置中。在相同的硬件上,以前最快的协议需要 2 秒,改进了 5 倍,而且需要更多的通信。 - 我们使用 VOLE 子域进一步优化了低通信设置的协议。我们实现了迄今为止最低的通信复杂度,用
比特的通信执行 个项目的 PSI,其中 是统计安全参数。这个协议在运行时间上仍然非常高效。一个 的 PSI 只需要 比特的通信就可以完成,而之前最好的 [RS21] 是 。 - 最后,我们将新的 OKVS 结构应用于 [PRTY19, RS21] 的电路 PSI 协议,观察到运行时间和通信量有 1.5 倍和 23 倍的改善。
1.2 概况
在第 2 节中,我们详细介绍了我们新的 OKVS 方案。
在第 3 节中,我们证明了我们将
在第 4 节,我们介绍了如何将我们的 OKVS 方案应用于 [RS21] 的 PSI 协议。从技术的角度来看,这个应用是比较直接的。然而,与现有技术相比,它立即给出了一个很大的运行时间和通信改进。这个结构同时实现了半诚实和恶意的安全。
然后,我们提出了一个优化,进一步减少了我们的 PSI 协议在半诚实环境下的通信开销。直观地说,PSI 协议的工作原理是,首先让接收方构建一个 OKVS
原始协议要求所有这些计算都在一个大小为
1.3 符号
我们用
2 我们的 OKVS 构造
我们首先描述了我们的核心 OKVS 结构,它将一组键值对
我们的算法从对一个实例密钥
第一步是进行三角化。这将
更详细地说,
这个算法的运行时间是
三角形算法 (Triangulation):我们的三角形算法运行时间为
该算法将矩阵
矩阵
然而,在某些情况下,
在第 3.3 节中,我们证明这个算法对于
我们注意到,在我们确实有一个关于
二进制
推理 1:
证明:……
推理 2:一个随机的范德蒙德矩阵和任何固定矩阵的总和以压倒性的概率拥有全行等级。
证明:……
这种方法的主要缺点是需要在一个大的域上进行乘法运算。然而,由于硬件对
参数:我们的核心结构有两个主要参数,扩展率
一般来说,我们观察到两种现象。第一个现象被称为相变 [DM08],在
由此,人们可能会得出结论,
2.1 聚类
尽管上述结构在所需的参数体系中实现了线性时间编码,但在对非常大的输入长度进行编码或解码时,它有一个主要的限制,例如
为了减轻这种影响,我们建议限制
虽然聚类有优势,但它会影响失败概率。为了解决这个问题,我们修改了
- 结合 (Combined):
可以定义为一个统一的函数 ,其中 。在这个表述中,我们利用了 的额外列可以在 聚类中共享的事实。由于 可能比 大几个系数,这将大大降低行的重量。总的来说,这种方法允许一个相对紧凑的编码,同时仍然能够进行聚类。 - 拆分 (Separate):另外,
可以被定义为有 个聚类,这些聚类与 相关联。如果 被映射到第 个聚类,那么 应该输出一个 中的均匀随机字符串,除了长度为 的第 个非重叠子串外,其他都是零。这样一来,我们就有效地创建了底层 OKVS 的 个独立实例。这种方法与之前的方法相比略显紧凑,但允许聚类之间有更大的独立性和更低的行权重。
总的来说,聚类允许算法处理大小为
聚类自然适合于多线程的实现。项目可以被映射到聚类中,然后一个线程可以处理每个聚类而不需要昂贵的同步。所有这些优化对编码和解码都是适用的。
3 分析和参数选择
我们的 OKVS 方案的性能关键取决于
3.1
我们从行权重
……
3.2 一般权重
……
3.3 我们算法的性能
……
3.4 结论
综上所述,我们将方程 2 中定义的
在本节的最后,我们提出一个挑选参数的具体策略。特别是,给定
- 按照方程 2 的定义计算
。 - 计算相变线的斜率为
,其中 被定义为方程 3 的右边。 - 求解
,使经过相变点 的直线以 的斜率通过点 。 - 计算
。
4 PSI
接下来我们谈谈我们结构的主要应用,即高效的隐私集合求交集。PSI 允许双方计算他们各自的集合
- 用我们的新结构取代 [PRTY20] 的 OKVS。
- 将 [RS21] 的 PSI 协议扩展到使用 VOLE 子域 [CRR21]。
正如下面所详述的,前者的改变改善了计算开销和通信开销。特别是,当我们用新的 OKVS 实例化 [RS21] PSI 协议时,PSI 协议能够在单线程的 0.4 秒内,或 4 线程的 0.16 秒内,在消费者的笔记本电脑上执行。此外,当 VOLE 子域优化被应用时,我们能够进一步减少通信开销。
我们的出发点是 [CRR21, BCG+19] 的 VOLE [子域] 协议。图 12 中描述的 VOLE 功能包括一个发送方和接收方。发送方输出一个随机的
下一阶段是利用 OKVS 的线性特性。特别是,对于
我们的快速实例化:就运行时间而言,我们协议更有效的实例是定义
低通信实例化:接下来,我们的目标是以运行时间为代价,尽量减少通信开销。首先,我们将把 B 实例化为最小的场,使
恶意的实例化:对于恶意安全,我们直接使用 [RS21] 的协议与我们的 OKVS 方案。
电路 PSI:我们利用了 [RS21] 的电路 PSI 协议。我们注意到,这个协议需要 OKVS 的一个额外的不经意属性。详见 A.2 节或 [RS21]。

图 9:半诚实的协议
半诚实的协议
参数:有两方,一个是发送方
协议:发送方输入
- 接收方对
和 进行采样,并计算 ,其中 。 - 发送方发送
,接收方发送 到 ,以维度 ,基域 和扩展 。双方分别收到 和 。 - 接收方将
和 发送给发送方,发送方定义 。 - 发送方将
以随机顺序发送给接收方。 - 接收方输出
。
5 评估
现在我们把注意力转移到我们结构的具体性能和与相关工作的比较上。我们的实现可以在 https://github.com/Visa-Research/volepsi 找到。综上所述,我们的构造在很大程度上超过了所有先前的工作。我们使用了 [CGS22, RR17] 的现有实现。这些协议都是在一台装有英特尔 i7 9750H 和 16GB 内存的笔记本电脑上进行基准测试。所有的构造都以
5.1 OKVS
我们首先比较了我们的结构和 [GPR+21] 的结构的编码和解码的运行时间。如图 1 所示,我们
我们还考虑了我们的结构在
更仔细地观察 [GPR+21] 的结构,我们观察到几个不同的和值得注意的细节。首先是 [GPR+21] 的编码器采用了不同的策略:1)贪婪地遍历图形以识别 2 核,2)使用二次元时间算法解决 2 核形成的整个子系统,3)贪婪地遍历图形以解决其余的行。与我们相比,他们的构造导致了几个缺点。首先是他们直接解决由 2 核形成的子系统,为此他们需要
其次,他们的编码器需要进行两次图的遍历。第一个是需要识别 2 核,第二个是需要识别非 2 核变量应该以何种顺序来解决。虽然是线性时间,但这种类型的图遍历是一个昂贵的操作。相比之下,我们的结构允许我们维护一个有序的列表,它准确地确定了行或列应该被解决的顺序,从而减少了运行时间。
此外,[GPR+21] 让他们的
为了获得任意小的失败概率的可证明的安全性,[GPR+21] 提出了一个巧妙的放大技术,它采用了一个失败概率为
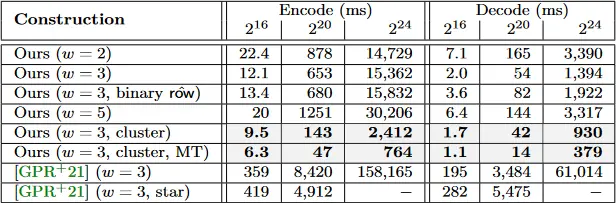
表 1:各种结构和输入大小
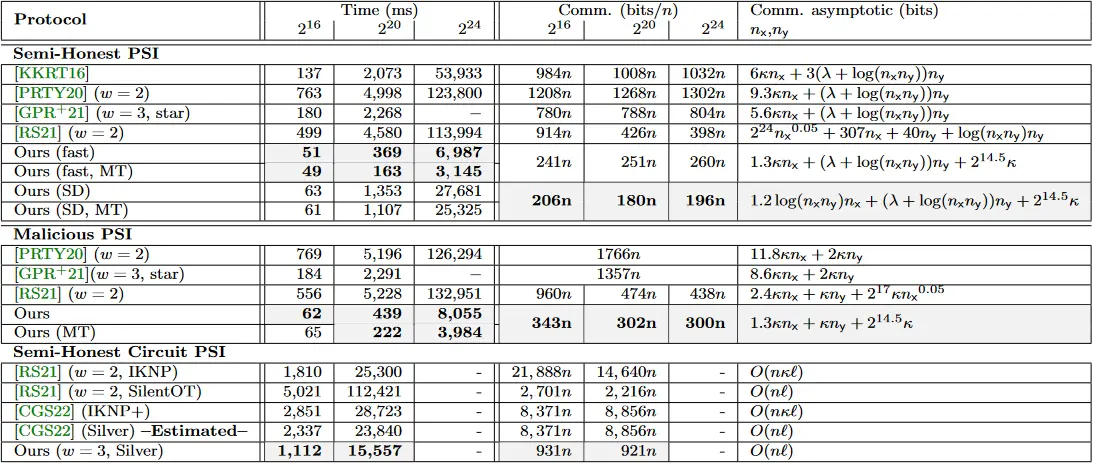
表 2:我们的 PSI 协议与相关作品的性能指标比较。
5.2 PSI
如第 4 节所述,我们提出了几种 PSI 协议的实例化。第一个是我们的 "快速" 变体,它被优化为小的运行时间。第二个版本,被称为 "SD",使用小域优化,实现了低通信开销。"MT" 表示每方使用了 4 个线程。
在所有情况下,我们的协议都大大超过了竞争对手。之前最快的半诚实协议是 [KKRT16],它使用了一个专门的 OPRF 类型的协议。我们的协议在单线程上的速度是 3 到 8 倍。我们的协议发送的数据大约少 2 到 5 倍。此外,我们的快速协议(带聚类)可以实现多线程,这使得
我们的 PSI 协议在运行时间和通信方面也超过了 [GPR+21] 几倍。[GPR+21] 是基于 [PRTY20] 的 PSI 协议,将原来的
我们的协议也比所谓的朴素 PSI 快,其中发送者发送其项目的哈希值。当使用 SHA256 时,我们比这个不安全的协议要快。与稍微不那么朴素的散列(AES - 散列)相比,运行时间和通信可以提高到比我们好 2 倍左右。对于不平衡的集合大小(
最后,从表 2 可以看出,我们的电路 PSI 协议在运行时间和通信方面明显优于现有技术。根据我们的比较,我们的协议快 1.5 到 5 倍,发送的数据少 15 到 2 倍。[CGS22] 可以说是最有竞争力的,需要 1.8 倍的运行时间和 10 倍的通信。他们的协议使用 IKNP 来评估他们协议结尾处的比较电路以及一些优化措施。那么人们可以问,使用 SilentOT+Silver 是否可以使他们的协议与我们的协议具有竞争力。他们的渐进通信将减少到和我们一样的
参考文献
- [BCG+19] Elette Boyle, Geoffroy Couteau, Niv Gilboa, Yuval Ishai, Lisa Kohl, Peter Rindal, and Peter Scholl. Efficient two-round OT extension and silent non-interactive secure computation. In Lorenzo Cavallaro, Johannes Kinder, XiaoFeng Wang, and Jonathan Katz, editors, Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, CCS 2019, London, UK, November 11-15, 2019, pages 291308. ACM, 2019.
- [BKM+20] Prasad Buddhavarapu, Andrew Knox, Payman Mohassel, Shubho Sengupta, Erik Taubeneck, and Vlad Vlaskin. Private matching for compute. IACR Cryptol. ePrint Arch., 2020:599, 2020.
- [Bol84] B ́ela Bollob ́as. The evolution of random graphs. Transactions of the American Mathematical Society, 286(1):257–274, 1984.
- [CGS22] Nishanth Chandran, Divya Gupta, and Akash Shah. Circuit-psi with linear complexity via relaxed batch opprf. Proceedings on Privacy Enhancing Technologies (PETs), 2022. https://eprint.iacr.org/2021/034.
- [CRR21] Geoffroy Couteau, Peter Rindal, and Srinivasan Raghuraman. Silver: Silent VOLE and oblivious transfer from hardness of decoding structured LDPC codes. In Tal Malkin and Chris Peikert, editors, Advances in Cryptology - CRYPTO 2021 - 41st Annual International Cryptology Conference, CRYPTO 2021, Virtual Event, August 16-20, 2021, Proceedings, Part III, volume 12827 of Lecture Notes in Computer Science, pages 502–534. Springer, 2021.
- [CT10] Emiliano De Cristofaro and Gene Tsudik. Practical private set intersection protocols with linear complexity. In Financial Cryptography, volume 6052 of Lecture Notes in Computer Science, pages 143–159. Springer, 2010.
- [DM08] Amir Dembo and Andrea Montanari. Finite size scaling for the core of large random hypergraphs. The Annals of Applied Probability, 18(5), 2008.
- [ER59] Paul Erd ̈os and Alfr ́ed R ́enyi. On random graphs i. Publ. Math. Debrecen, 6:290–397, 1959.
- [FK21] Alan Frieze and Michal Karo ́ nski. Introduction to random graphs, 2021.
- [FKK03] Andr ́as Frank, Tam ́as Kir ́aly, and Matthias Kriesell. On decomposing a hypergraph into k connected sub-hypergraphs. Discret. Appl. Math., 131(2):373–383, 2003.
- [For17] Quentin Fortier. Aspects of connectivity with matroid constraints in graphs modeling and simulation. Universit ́e Grenoble Alpes, NNT : 2017GREAM059, 2017.
- [GPR+] Gayathri Garimella, Benny Pinkas, Mike Rosulek, Ni Trieu, and Avishay Yanai. OBDBasedPSI . github.com/cryptobiu/OBDBasedPSI.
- [GPR+21] Gayathri Garimella, Benny Pinkas, Mike Rosulek, Ni Trieu, and Avishay Yanai. Oblivious key-value stores and amplification for private set intersection. In Tal Malkin and Chris Peikert, editors, Advances in Cryptology - CRYPTO 2021 - 41st Annual International Cryptology Conference, CRYPTO 2021, Virtual Event, August 16-20, 2021, Proceedings, Part II, volume 12826 of Lecture Notes in Computer Science, pages 395425. Springer, 2021.
- [HEK12] Yan Huang, David Evans, and Jonathan Katz. Private set intersection: Are garbled circuits better than custom protocols? In 19th Annual Network and Distributed System Security Symposium, NDSS 2012, San Diego, California, USA, February 5-8, 2012. The Internet Society, 2012.
- [IKN+20] Mihaela Ion, Ben Kreuter, Ahmet Erhan Nergiz, Sarvar Patel, Shobhit Saxena, Karn Seth, Mariana Raykova, David Shanahan, and Moti Yung. On deploying secure computing: Private intersection-sum-with-cardinality. In EuroS&P, pages 370–389. IEEE, 2020.
- [IKNP03] Yuval Ishai, Joe Kilian, Kobbi Nissim, and Erez Petrank. Extending oblivious transfers efficiently. In CRYPTO, volume 2729 of Lecture Notes in Computer Science, pages 145–161. Springer, 2003.
- [KKRT16] Vladimir Kolesnikov, Ranjit Kumaresan, Mike Rosulek, and Ni Trieu. Efficient batched oblivious PRF with applications to private set intersection. IACR Cryptol. ePrint Arch., page 799, 2016.
- [Luc90] Tomasz Luczak. Component behavior near the critical point of the random graph process. Random Struct. Algorithms, 1(3):287–310, 1990.
- [Mea86] Catherine A. Meadows. A more efficient cryptographic matchmaking protocol for use in the absence of a continuously available third party. In IEEE Symposium on Security and Privacy, pages 134–137. IEEE Computer Society, 1986.
- [NTY21] Ofri Nevo, Ni Trieu, and Avishay Yanai. Simple, fast malicious multiparty private set intersection, 2021. https://ia.cr/2021/1221.
- [OOS17] Michele Orr` u, Emmanuela Orsini, and Peter Scholl. Actively secure 1-out-of-n OT extension with application to private set intersection. In CT-RSA, volume 10159 of Lecture Notes in Computer Science, pages 381–396. Springer, 2017.
- [Oxl06] J.G. Oxley. Matroid Theory. Oxford graduate texts in mathematics. Oxford University Press, 2006.
- [PRTY19] Benny Pinkas, Mike Rosulek, Ni Trieu, and Avishay Yanai. Spot-light: Lightweight private set intersection from sparse OT extension. In CRYPTO (3), volume 11694 of Lecture Notes in Computer Science, pages 401–431. Springer, 2019.
- [PRTY20] Benny Pinkas, Mike Rosulek, Ni Trieu, and Avishay Yanai. PSI from paxos: Fast, malicious private set intersection. In Anne Canteaut and Yuval Ishai, editors, Advances in Cryptology - EUROCRYPT 2020 - 39th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, May 10-14, 2020, Proceedings, Part II, volume 12106 of Lecture Notes in Computer Science, pages 739–767. Springer, 2020.
- [PSSZ15] Benny Pinkas, Thomas Schneider, Gil Segev, and Michael Zohner. Phasing: Private set intersection using permutation-based hashing. In USENIX Security Symposium, pages 515–530. USENIX Association, 2015.
- [PSZ14] Benny Pinkas, Thomas Schneider, and Michael Zohner. Faster private set intersection based on OT extension. In USENIX Security Symposium, pages 797–812. USENIX Association, 2014.
- [PW88] Christos H. Papadimitriou and David Wolfe. The complexity of facets resolved. J. Comput. Syst. Sci., 37(1):2–13, 1988.
- [RR17] Peter Rindal and Mike Rosulek. Malicious-secure private set intersection via dual execution. In ACM Conference on Computer and Communications Security, pages 1229–1242. ACM, 2017.
- [RS21] Peter Rindal and Phillipp Schoppmann. VOLE-PSI: fast OPRF and circuit-psi from vector-ole. In Anne Canteaut and Fran ̧cois-Xavier Standaert, editors, Advances in Cryptology - EUROCRYPT 2021 - 40th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, October 17-21, 2021, Proceedings, Part II, volume 12697 of Lecture Notes in Computer Science, pages 901930. Springer, 2021.
- [Wal21] Stefan Walzer. Peeling close to the orientability threshold - spatial coupling in hashingbased data structures. In D ́aniel Marx, editor, Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms, SODA 2021, Virtual Conference, January 10 - 13, 2021, pages 2194–2211. SIAM, 2021.
- [ZLS06] Jianmin Zhang, Sikun Li, and ShengYu Shen. Extracting minimum unsatisfiable cores with a greedy genetic algorithm. In Abdul Sattar and Byeong-Ho Kang, editors, AI 2006: Advances in Artificial Intelligence, 19th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, December 4-8, 2006, Proceedings, volume 4304 of Lecture Notes in Computer Science, pages 847–856. Springer, 2006.